NeuroCube
Overhauling The Navigation System
There is a new navigation system in the works that leverages VSLAM for localization and mapping, Nvblox for 3D scene reconstruction and cost mapping, Nav2 for path planning and obstacle avoidance, and an LLM-based decision-making system for high-level task reasoning and goal setting.
Previous System vs. New System (What Changed?)
The previous system simply outputted motor commands based on LLM analysis of what the user wants and object data collected from the camera (no map building or path planning).
This works for simple scenarios where the environment is well-known and static. For scenarios that involve moving obstacles such as people or pets and tasks that require exploration or longer-term navigation, this system would fail since the LLM only sees snapshots of the world before each output command with no global map view.
The new system will use a cost mapper (Nvblox) and navigation planner (Nav2) to enable real-time path planning and dynamic obstacle avoidance using high-frequency localization and mapping data (VSLAM). It will be controlled by an LLM-based decision-making system that can reason about high-level tasks and environmental cues to decide where to go next.
LLM Control System For Navigation
Currently, I am developing a system that allows the robot to decide for itself where to go based on a given task and environmental cues. This works by sending task information and semantic descriptions of the environment to the LLM and converting LLM outputs into actionable commands for Nav2.
NOTE: The LLM cannot accurately determine facing rotation, so I am omitting the need for the model to output a target rotation (yaw) for now and just focusing on target position (x, y). The target rotation is calculated as the look at rotation from the robot’s current position to its target position.

What The LLM Receives
- Task description (natural language)
A description of what the robot is supposed to do, e.g. "Find an [object] and go to it."
- ESDF (Euclidean Signed Distance Field) cost grid:
[val00, val01, ..., val0n;
val10, val11, ..., val1n;
..., ..., ..., ...;
valm0, valm1, ..., valmn]
- Semantic dictionary of object labels and their grid coordinates:
{"object1": "(x, y)", "object2": "(x, y)", ...}
- Navigation feedback:
Navigation towards (x, y) failed / canceled / succeeded.
What The LLM Outputs
- Reasoning: What the LLM was thinking while producing the output.
- Goal coordinates: [x, y]
- Task status: (in progress, completed, failed)
{
"REASONING": "The task is to ... I should ...",
"COORDINATES": [x, y],
"TASK STATUS": "IN PROGRESS"
}
Towards Agentic AI With Question Asking
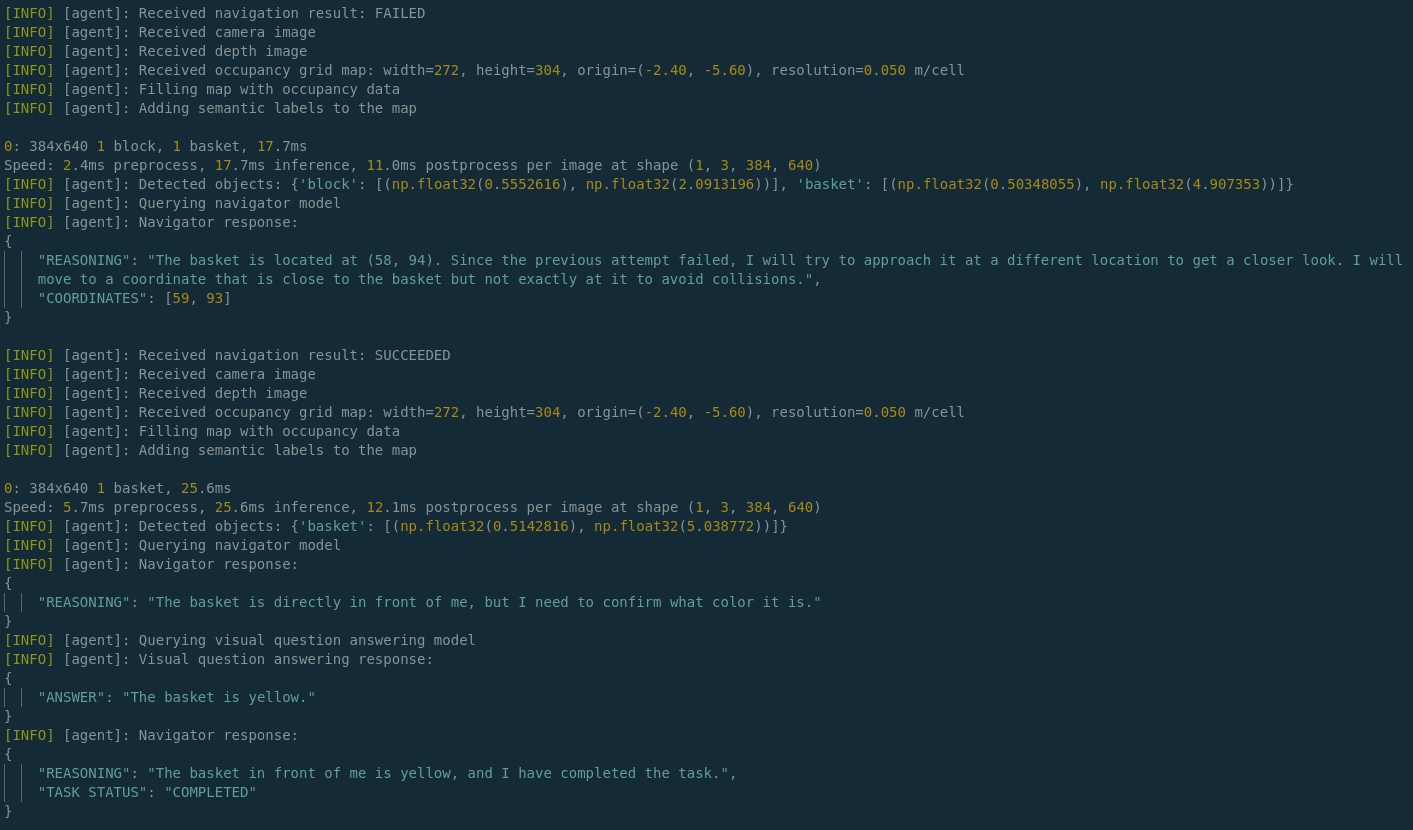
One challenge with using LLMs for navigation is that they may not always have enough information to make informed decisions. For example, if the robot is tasked with finding a yellow basket but there is only information about a basket in the environment, the LLM needs to be able to ask clarifying questions about the color in order to proceed effectively.
At a basic level, the LLM is currently able to perform the following steps to gather information:
- Analyze textual-semantic information in the form of a cost grid and a dictionary of detected object labels.
- Determine what information it’s missing, such as color, which the object detection / segmentation model, YOLO, does not provide.
- Route this query through an MCP (Model Context Protocol) tool call that requests additional information from a VQA (Visual Question Answering) model, BLIP, to ask for the missing information.
- Receive the answer from BLIP and become more confident in completing the task.
Last few lines of logged output demonstrating this as the robot approaches a yellow basket:
Next Steps
- Deploying to the physical robot
- The digital twin is a great way to test and validate navigation algorithms in a safe and controlled environment.
- The next step is to deploy the navigation system to the physical robot and test it in real-world scenarios.
- More MCP tools to broaden assistant capabilities!
- Currently, the only supported tools are the Search and RAG tools, which allow the robot to generate contextually relevant responses based on external knowledge sources.
- However, the robot can be so much more than just a search and retrieval engine! I’m envisioning many more tools and am in the process of planning and designing them.